In the last blog post we conducted a deep dive on “The Snail,” a conceptualization of the ways in which the clinical research industry has begun moving towards continuous evidence generation. As this new evidence-gathering landscape emerges, the industry has begun blending clinical trial results with real-world data and the evidence generated from it, as well as other post-approval data sources.
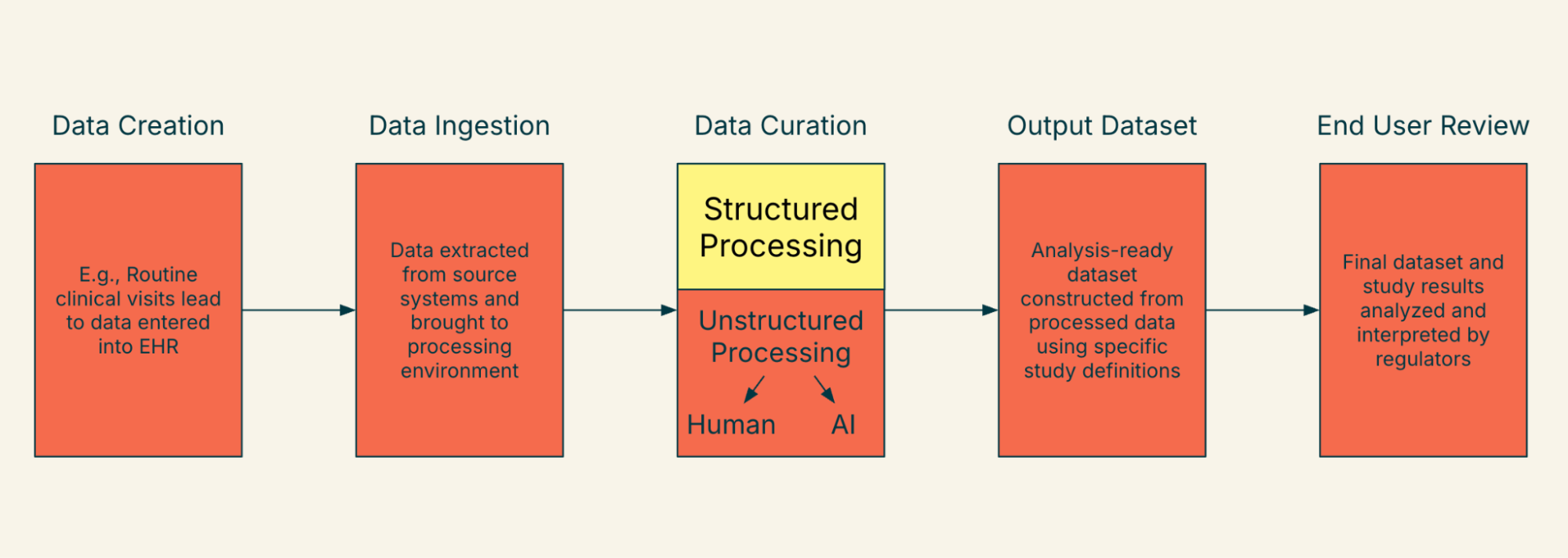
As we think about a future state where we are able to ingest and digest such a variety of data, one of the key changes we anticipate is the rise of data mosaicism. To illustrate our point, it may be helpful to begin with the “lifecycle” of a real-world data element from a single data source, as it illustrates the coming complexity. Figure 1 illustrates this concept, tracing a data element from creation at the point of care to subsequent ingestion, curation, creation of the output dataset, and ultimately, end user review. This lifecycle contains many steps, transformations, involved parties, and changes in chain of custody.
Figure 1. Life of a Data Element as Interpreted by Regulators and Other End Users - Single Health System/Data Source
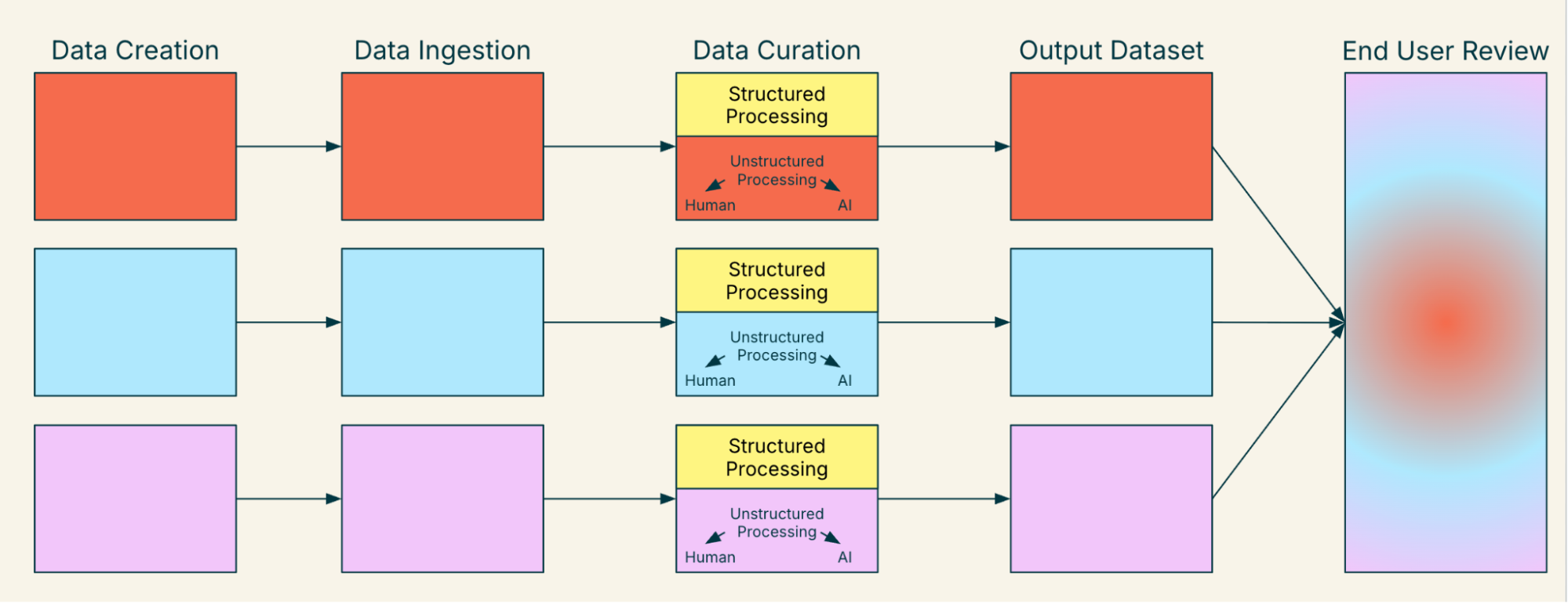
The process grows in complexity when you incorporate data elements from multiple health systems or data sources. Each data input may use different ingestion or curation approaches, resulting in differences in output datasets. This complexity is illustrated by Figure 2. This concept can be referred to as “data mosaicism” and can add great complexity to analysis plans and end user review.
Figure 2. Life of a Data Element as Interpreted by Regulators and Other End Users - Multiple Health Systems/Data Sources
One of the biggest opportunities for the healthcare industry involves achieving data mosaicism not just among real-world data sources, but data mosaicism among all types of data. As discussed earlier, the only difference between real-world data and clinical trial data are variations in the circumstances and controls through which the data are collected. As we strive towards a more interoperable future, it is imperative that we grow our understanding of more complex mosaicisms (e.g., the challenges related to incorporating RWD collected via FHIR into a clinical trial submission). To do this, we must harmonize our evaluations of different sources of data. For clinical trial data, the industry relies on source data verification and study monitoring as markers of data quality. It is widely accepted that these concepts can guarantee data quality across different clinical trials. This existing conceptualization requires modernization as we approach clinical data mosaicism and encounter variations in implementation and mapping approaches. Indeed, there is even an additional layer of data mosaicism that occurs when we acknowledge that for any data element, we will likely need a combination of EHR-sourced data and case report form (“CRF”)-sourced data. For example, imagine that smoking status cannot be reliably mapped from the EHR in 30% of instances; it will need to be completed by CRF or treated as missing.
Highlander Health Institute is actively working on accompanying solutions to this very question and are developing and testing a variety of approaches in collaboration with partners around the globe that seek to improve our collective ability to digest, interpret, and rely on data from a variety of sources and inputs. Please contact us if you would like to learn more about our comments or our ongoing work to solve pressing issues facing the evidence generation and health technology ecosystems. In our next blog in our “Mosaic Medicine” series, we will “futurecast” a bit and discuss other ways in which the underlying pillars of evidence generation and drug approval may shift in the coming years.
Read Mosaic Medicine Part 2 on The Snail here, and Part 1 on A Vision of the Shifting Clinical Evidence Landscape here.
Mosaic Medicine
Institute | Resources
Public Policy
Technology
